
How to design a Cyber Vulnerability Management program that maximizes the ROI of your team’s work to be compliant and maximize the reduction of business risk at the same time.
If the title of this article caught your eye, you likely work in cybersecurity or IT in a regulated industry and have felt the pain of doing work that “had to be done” to meet the demands of an inspector or auditor. You probably knew (or had a very strong suspicion) that some or much of this work wouldn’t have a meaningful impact on your organization’s cybersecurity posture, but you had to do the work nonetheless. Sometimes you just have to swallow your opinion, do the work, check the boxes, and move on.
In the end, you’re going to be working on two sets of “fixes”: 1) The work that the regulator expects and requires, and 2) the set of fixes that you believe are necessary based on what you know about your network.
Where those two sets overlap is the sweet spot. It’s the area where you are complying with your regulatory requirements while also reducing real risk. We want that overlap to be as large as possible, but the reality is that sometimes you and the regulator are going to be very far apart in what you see as the important issues.
There are a few reasons why a regulator, auditor, or inspector may require you to do work that you believe is unnecessary.
- First, in some cases, regulations and regulators are behind the times. They are solving for last year’s (or last decade’s) problems. They’ve seen a problem that caused serious issues in your industry, and now it’s on their checklist. In some cases, it may literally take an act of Congress to get that checklist item removed.
- Second, they are seeing things that are actively causing real problems at other organizations, but you may not know about them yet because the item hasn’t hit the news yet. There may not even be a CVE for it, but they’ve been discussing as a team and are recommending it as best practice.
- Finally, one of you may simply be wrong. We work in a very complex, very technical field with a lot of specialization. Put one random Vulnerability Management professional and one random regulator in a room at any time and discuss 50 vulnerabilities and odds are you won’t agree on everything. Since some of what we do is more art than science, there’s going to be a variety of opinions.
It’s crazy out there
Networks are growing in complexity, vulnerability disclosures are accelerating, organized cybercrime is a lucrative and growing industry, and we don’t have enough qualified people to throw at the problem. These are the challenges all enterprise cybersecurity teams face. But by far the most intractable problem is that as an industry we don’t have a standard way to communicate which vulnerabilities carry more risk in a given network than another, and I would argue that we can’t have one.
Your mind may be going to CVSS scores or vulnerability scanners right now, but as others have pointed out, the CVSS scoring system has critical flaws when used to communicate risk, and neither CVSS scores nor vulnerability scanners know enough about your network to actually capture the amount of business risk posed by any vulnerability on your network.
Let me prove it with two simple examples:
1) Say your scanner says you have a “critical” vulnerability (a score of “10” on the CVSS scale) that allows an arbitrary attacker to gain root on the box. The box also has a database on it named “CUSTOMER_CREDIT_CARDS”. Upon your inspection, you find out it’s a development box with a test database on it that has exactly one, fake record. The business risk of someone exploiting that “critical” vulnerability and exfiltrating anything important is extremely low.
2) You have two medium-level vulnerabilities 12 hops apart on a network. Neither of the boxes contain critical assets. Your vulnerability scanner tells you these two vulnerabilities are a “medium” risk and therefore a lower priority for remediation. But you go look at the boxes and a lightbulb goes off. You write a 5 line proof of concept script that chains these two vulnerabilities together allowing access to a third box with LOCAL_SYSTEM access. That third box has a million records of PII including social security numbers. These two “mediums” chained together could mean millions of dollars in fines, you “resigning to spend more time with your family”, and perhaps the death of the company. Remember, ”attackers don’t think in terms of vulnerabilities, but in terms of graphs.”
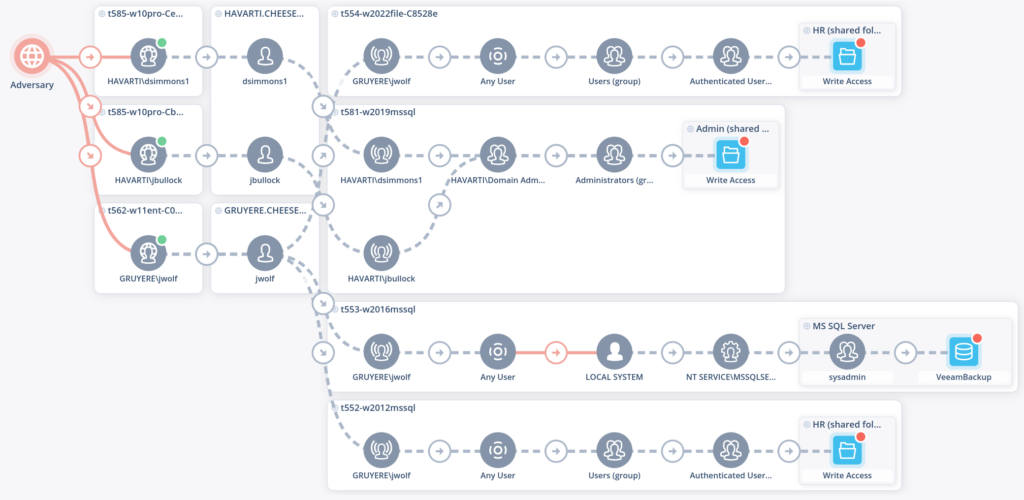
Crucial Context
What other criteria made the crucial difference in knowing which vulnerability to ignore for now, and which to fix immediately? There are six things.
1) Where the asset at the end of the attack is
2) how much it is worth
3) what your topology and access control lists look like
4) user behavior and permissions on the boxes along the way
5) applications running on the hosts and what privileges they have6) the ease and practicality of the attack that would have to be executed. In short, “context”.
Without having all the context, you won’t know that a critical CVE for someone else could be of no consequence at all to you. In fact, a CVSS score of 8 in one location on your network may contribute orders of magnitude more risk than the same vulnerability somewhere else. The only way to know the business risk that any vulnerability contributes to your organization is by exhaustively looking at the context it exists in.
What does this have to do with regulators? Everything.
Here’s a hypothetical: You and your inspector/auditor are looking at two vulnerabilities and trying to decide which is most important. What happens? Well, without context, it’s your opinion against the policy, experience, and gut instincts of the regulator. Tie goes to the regulator.
So, the answer is right in front of us. Gather the context for those two vulnerabilities and compare them in situ. Doing this isn’t that hard from a technical point of view, and the benefits are clear. In an afternoon, you’ll have an objective way to validate the business risk of one over the other.
But, what about scaling the process? It’s just more of the same. First, you need to know each vulnerability on your network–this is easy as vulnerability scanners are cheap and have been around for 25 years. Next, you need to know, exhaustively, all the context around each vulnerability, and how that vulnerability can be amplified in risk through any number of combinations with the other vulnerabilities on your network. “Wait,” you say, “I’ve got 4,500 users, 6,000 hosts, a cloud infrastructure, and countless other devices on my networks.” Yep, sucks to be you.
But there’s hope. Below, we’ll argue it’s possible for healthcare providers, legal services companies, financial services organizations, federal data centers and other regulated organizations to not only be better prepared for for their annual penetration test, but pass their annual compliance inspection, and objectively prove how much risk they have mitigated in the last two, six, or 12 months. Along the way, they’ll be protecting their organization from future threats, meeting regulatory requirements, and looking good in front of the board of directors.
Here’s the path you need to follow
With so much at stake, you need to be objectively sure and able to prove the relative business risk of every vulnerability against every other vulnerability.
To do that, first identify the critical assets on your network. Don’t overthink it. You don’t necessarily need to attach a financial value to each asset (although it’s great if you do), just rank hosts with a “Criticality Score” of 1 to 100, with 100 being the most critical systems or hosts on your network, and 1 being the web-connected Coke machine. Even if you just flag the important systems and give no rating at all to the others, you’re moving in the right direction.
Second, take one instance of the first vulnerability and spend the time needed to gather all the context around just one instance of that vulnerability. After you are done, then do the same thing for the next vulnerability and repeat until you’ve gathered that context for each.
Finally, come up with a scoring system that works for you. It’s not as complicated as it sounds. Here are some examples:
- Is the vulnerability easy to exploit (are there scripts available that will do the work for you)? Hard to exploit vulnerabilities should get a lower score on this metric.
- Does exploiting the vulnerability crash machines? Ones that never crash machines get a higher score because they are harder to detect.
- Check to see if all the conditions needed for the attack to succeed on that host are met. E.g., for an Edge browser bug: Examine logs and determine if there end-users using Edge on that machine? No browser activity on that machine means that this vulnerability gets a low “Conditions Met” score.
- Does getting increased access on this machine get the attacker closer with more access to a critical asset? Machines that get you closer, score higher; and machines with only very low access rights for users score lower.
- Find choke points. If there are six “pathways” between a potential attacker and a critical asset, find out how many of those pathways pass through the same instances of vulnerability. Find the point on the graph where, if you fixed that one vulnerability, you would knock out multiple pathways. Points on the graph with lots of pathways going through an instance of a vulnerability score high and ones with only one or two score lower.
You get the idea. Come up with a dozen or so criteria.
Now start adding up scores. Say that you have chosen a range of 1-100 for your scores and you have 15 criteria. An instance of a vulnerability that has a score of 1,300 is a VERY risky vulnerability and should be the next patch IT works on. A vulnerability with scores under 200 is much less important right now.
Show them the scores
And with that, we’ve found the key to reducing business risk on your enterprise network while making your regulators very happy. Just show them the scores. “Show your work,” as my 5th grade math teacher used to say. Regulators are reasonable people, and even if they disagree with one or two of your scores and think a 70 should be an 82, they will see that the aggregate number will be a very objective measure of business risk.
In fact, in the absence of this objective data, the regulator is probably just as correct as you (maybe more correct) when she says “just use this checklist, it’s what we used at the last five Credit Unions we inspected”. But if you have data — hard, objective scores — I bet you will convince them 9 times out of 10 on what you chose. They will be convinced because they can see the “why” behind your judgments.
Automation
You might be thinking at this point, “That is a lot of context to gather and score” and you are right, but automation is your friend. The best thing you can do after figuring out what your criteria are is to start figuring out ways to query your hosts for the context you need and scoring something. If the only metric you’re using now is CVSS scores, then you have your work cut out for you, but it’s worth it. Each new criteria you add to your set is going to give you a multiplier effect with regard to the objectivity and credibility of the relative scoring of vulnerabilities.
Final words
The time spent on gathering context through automation, applying relative scores, and then prioritizing vulnerabilities in relation to the holistic business risk they contribute to your enterprise-wide threat model, is worth it. Here are some reasons why:
- We’ve already shown how doing this increases the overlap in the diagram and allows you to prioritize your valuable resources addressing the vulnerabilities that are contributing the most risk while making your regulator happy and more confident that you are giving the right things your attention. That’s much more cost-effective and risk-reductive than “checking the boxes” the regulator brings up and then spending what little time you have left on addressing the things you think are really a danger to your network.
- You’re doing “Predictive Vulnerability Management”, and it is a truism that an ounce of prevention (in this case, risk-based remediation) is better than a pound of cure (forensics, recovery, and rebuilding) after a successful attack.
- The results are asymptotic. As you are constantly addressing the most important risks week after week, I can guarantee you will run into a power law distribution where 80% of your risk each week is coming from 20% (or less) of your vulnerabilities. By always picking vulnerabilities off the top of that list, you will drive your total enterprise risk down with the highest possible ROI. Not only that, but you will also drive it down to a plateau and keep it there. This means that when a new, outsized-risk appears on your network (and it will) you’ll spot it easily and know that you need to address it quickly. Using Predictive Vulnerability Management you are no longer looking for risk among noise (needles in haystacks), but you’ll see clear spikes in risk.
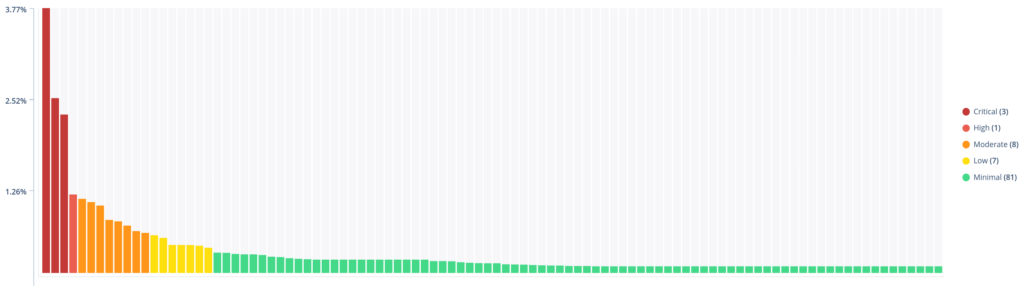
Conclusion
By working with regulators to agree on shared understanding of risk, using detailed context to better score objective business risk, and using automation to gather context and score vulnerabilities; you will make regulators happier faster, rapidly drive down risk in your organization in a cost effective way, and be better able to identify new and out-sized risks as they appear on your network.
About the Author
James Dirksen is the founder and CEO of DeepSurface Security. He has 26 years of experience in cybersecurity and started his career as a security and networking engineer at the Pentagon working for Northrop Grumman. He and his family moved to Portland in 1997 and he has since worked for PWC engineering security solutions for Fortune 1000 companies, as a VP of Business Development and Product for Procera (now Sandvine), VP of Product and Sales for RuleSpace (now Symantec), and as VP of Product at Galois in Portland leading efforts to commercialize DARPA funded cybersecurity prototypes.
About DeepSurface Security
DeepSurface Security is the first automated Predictive Vulnerability Management suite of tools that helps cybersecurity teams automate the collection of all the context needed, analysis of the threat model, and prioritization of vulnerabilities on their network. Created by a veteran cybersecurity team, DeepSurface Security is trusted by enterprise CISOs and Vulnerability Management teams to identify and objectively quantify the business risk posed by vulnerabilities on their networks. Headquartered in Portland, Oregon, DeepSurface is a privately held company funded by Cascade Seed Fund, SeaChange Fund, and Voyager Capital. To learn more visit www.deepsurface.com.